Insights on AlphaZero
In last week's post, Talking About AlphaZero, I noted:-
The most detailed discussion was on neutral ground (talkchess.com) with participants from the Stockfish & Leela communities, from DeepMind, and from other (mostly) knowledgeable experts.
That introduction led to a long thread titled Alphazero news. The contributor from the DeepMind team was Matthew Lai, whom we have already seen twice on this blog:-
- 2017-12-10: Giraffe and AlphaZero
- 2018-12-07: AlphaZero Is Back!
Let's eavesdrop on some of Matthew Lai's thoughts about AlphaZero. The 'Q's were from various members of the Talkchess community.
by matthewlai >> Fri Dec 07, 2018 1:18 am • Q: Do you have an opinion on whether AlphaZero would beat the latest version of Stockfish? • A: I don't think it would be really useful for me to speculate on that. Suffice to say, AlphaZero today is not the same as AlphaZero in the paper either.
...
by matthewlai >> Fri Dec 07, 2018 4:20 pm • Q: Is most of the code for Alphazero Python code, or is the pseudocode transcribed from a different language like C++? • A: AlphaZero is mostly in C++. Network training code is in Python (Tensorflow). Network inference is through C++ Tensorflow API.
...
by matthewlai >> Sat Dec 08, 2018 3:17 am • Q: Does this mean Giraffe will get some updates in the future ? • A: Afraid not! AlphaZero is taking up all my time these days, and it's a very exciting project with lots of uncharted territory ahead :). AlphaZero is basically what I ever wanted Giraffe to become... and then a lot more. I have never been this excited about computer chess my whole life.
Many of Lai's comments were about technical details arising from the pseudocode that was released with the paper in Science magazine. He also referred to the architecture of the neural network.
by matthewlai >> Sat Dec 08, 2018 11:45 am • Q: Could you divulge the size of the network file that A0 used ? • A: The details are in supplementary materials -- 'Architecture: Apart from the representation of positions and actions described above, AlphaZero uses the same network architecture as AlphaGo Zero, briefly recapitulated here. The neural network consists of a "body" followed by both policy and value "heads". The body consists of a rectified batch-normalized convolutional layer followed by 19 residual blocks. [...]'
What about DeepMind's commercial intentions?
by matthewlai >> Tue Dec 11, 2018 3:20 am • Q: Are there any plans in the pipeline to commercialize AlphaZero? • A: Cannot talk about anything unannounced unfortunately!
...
by matthewlai >> Tue Dec 11, 2018 11:50 am • Q: Has DeepMind used the services of any past or present GMs or IMs while creating A0? • A: There wasn't one for AlphaZero during development of this Science version, but we did have GM Matthew Sadler look at the games in the paper and to pick the ones he thought was most interesting. We also collaborated with him later on the World Chess Championship commentary, and their upcoming book. We obviously learned a few things about AlphaZero in the process.
The longest discussion was about the use of opening books during the tests against Stockfish. It is too detailed and too technical to repeat here, although I might attempt to summarize it in another post. The timestamp on the following message locates the full discussion.
by matthewlai >> Tue Dec 11, 2018 12:13 pm • Q: I have a question, that came up while I was greedily digging through the papers. One number seems to be very odd to me: In the match against Stockfish [SF] with opening book Brainfish, when AlphaZero [AZ] play black, it gets ~2/4 % wins against SF8/SF9, but ~18% wins when playing against the supposedly stronger Brainfish [BF]?! [...] • A: It's hard to say and I don't want to speculate much beyond what we have data to support, but my guess (and I can very well be wrong) is that there's much less diversity when SF uses the BF opening book. We already didn't have a lot of diversity from start position, but start position at least has several variations that are roughly equal and both AZ and SF have enough non-determinism (through multi-threaded scheduling mostly) that we still got reasonably diverse games.
With the BF games we took out most of SF's non-determinism, and it's possible that SF just ends up playing a line that's not very good often, or something like that. In fact, we found that as we explained in the paper, if we force AZ to play some sub-optimal moves (in its opinion) to enforce diversity, we win even more games! I realise there's a lot of hand-waving here, but there are just too many possibilities.
I don't remember the number of games played, but it was more than high enough that the result is statistically significant. We decided to release games from the start position and TCEC positions as the main result of the chess part of the paper because start position is more scientifically pure (they were actually playing the game of chess, not a game that's just like chess except you are forced to start from these positions), and from TCEC openings we show that we can play well even in openings that it wouldn't normally play.
One chart, showing the progress of traditional engines ('Alphazero news', p.38), also caught my attention. The dates on the x-axis run from 2005-02 through 2018-12. The numbers on the y-axis go from 2700 to 3500. Where will ratings go with the NN engines?
Top programs' ratings over time
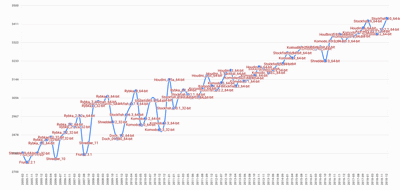
http://rwbc-chess.de/pics/chart.png
The link under the chart leads to a magnified version. Getting back to Matthew Lai, at one point he mentioned,
I am the only person on the team familiar with conventional chess engines.
That makes his insights into AlphaZero's development and test processes particularly valuable.
***
Later: I should have mentioned the signature that is appended to every matthewlai comment:-
Disclosure: I work for DeepMind on the AlphaZero project, but everything I say here is personal opinion and does not reflect the views of DeepMind / Alphabet.
Google, DeepMind, Alphabet. Does it take a PhD in high-tech organization charts to understand their relationship?



No comments:
Post a Comment