Google Search Coverage
I ended last week's post, Google Search Console ('to catch up on the many Google notices I've received since the beginning of the year'), on hold:-
The 'Performance' page for the old HTTP version of my site confirmed a large drop in search traffic since 2018-08-17. This should have been balanced by a corresponding increase in search traffic for the new HTTPS version, but Google told me 'Oops, you don't have access to this property'. After procuring the access, I received the message 'Processing data, please check again in a few days'.
A few days later, I received another email from Google:-
To: Owner of https://www.mark-weeks.com/ • Google systems confirm that on Sep 13, 2018 we started collecting Google Search impressions for your website in Search Console. This means that pages from your website are now appearing in Google search results for some queries. Here’s how you can monitor your site’s performance in search using Search Console.
The message pointed to a console resource called 'Coverage' that showed me how many of my pages were included in Google's search engine results. Here are the current charts for both the old and new versions of the site.
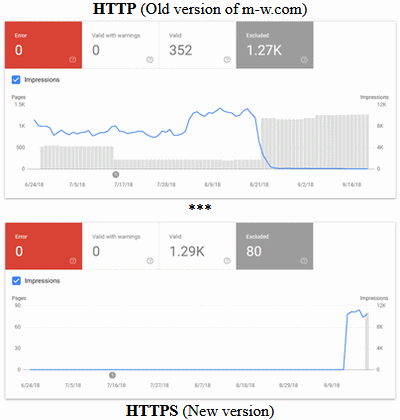
The rectangles at the top of each display say 'Error' (in red), 'Valid with warnings', 'Valid' (both white), and 'Excluded' (gray). Why are some pages on the old HTTP version marked 'Valid'? More importantly, why are other pages on the new HTTPS version marked 'Excluded'? The 'Excluded' pages fall into two categories:-
- 'Duplicate without user-selected canonical'
- 'Crawled - currently not indexed'
The Google help page, Index Coverage Status report (support.google.com), explains,
Duplicate page without canonical tag: This page has duplicates, none of which is marked canonical. We think this page is not the canonical one. You should explicitly mark the canonical for this page. (We're working on a tool to show you which page was selected as canonical, but we're not quite there yet.)
and
Crawled - currently not indexed: The page was crawled by Google, but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling.
What does 'canonical' mean? From Consolidate duplicate URLs:-
If you have a single page accessible by multiple URLs, or different pages with similar content (for example, a page with both a mobile and a desktop version), Google sees these as duplicate versions of the same page. Google will choose one URL as the canonical version and crawl that, and all other URLs will be considered duplicate URLs and crawled less often.
For my site this refers to small pages that show some aspect of a position, like a chess trap, where all of the pages are structured similarly. The pages marked 'Crawled - not indexed' are of the same type. It's not really a problem, although my obsession with a topic that has nothing to do with chess might be a problem. In my next post I'll move on to another topic.



No comments:
Post a Comment